GitHub
GitHub
 All Technical Projects
All Technical Projects Portfolio Home
Portfolio Home
Project Overview
Cornucopia is an app which helps users manage kitchen pantries and minimize food waste
Users are able to add grocery items to their pantry, and Cornucopia will notify them when their items are expired. Pantry items can be added individually, or in batches by scanning grocery receipts.
Additionally, users will be notified if any food item within their pantry has been recalled for saftey reasons.
Cornucopia also is able to scan user pantry, and suggest meals which use items that may expire soon.
Development/Implementation
Image Processing + Text Recognition
Cornucopia enables users to upload receipts to add items to their pantry in bulk. After uploading the image to the server, Cornucopia scans the receipt for grocery items, which are then sent back to the user to confirm. PyTesseract is the tool used for text recognition within each image, but because PyTesseract is able to read text from any image, this process can sometimes be slow. Images are optimized for PyTesseract by first compressing them (by downscaling), and then gray-scaling the image
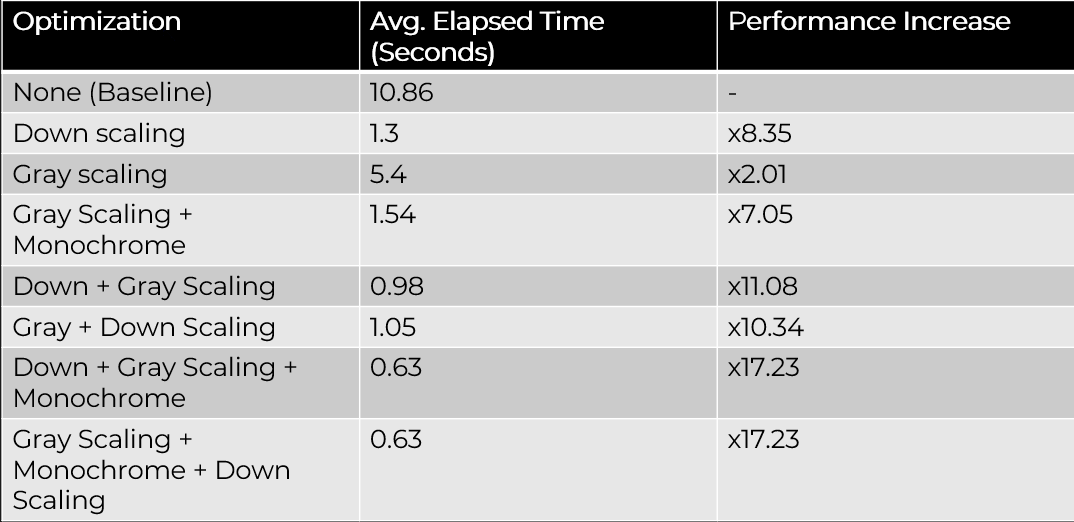
The table below shows data based on tests developed to find the ideal image optimizations, where a combination of down-scaling, gray-scaling, and monochromatization were tested. The results are an average based on 40 large images. Monochromatization had significant performance benefits, however this was at the cost of accuracy, which was significantly worse due to how aggresive monochromatization can be.
I also played around with the idea of further cropping the image after down-scaling, which was accomplished by cropping the image based on black pixel density (after monochromatization), however this had negligable performance benefits, and suffered from the same accuracy issues.


Text-Filtering + Correction
With the receipt scanned, the text from the receipt must be filtered, since not all the text is relevant to the grocery items. Luckily, PyTesseract is able to identify line breaks, and as grocery receipts generally lay out their items on separate lines, we simply need to identify where the grocery items are located, and then discard the rest of the text. For example, information after any kind of total/subtotal information is irrelevant to Cornucopia's function.
This text is filtered using a combination of Regular Expressions, as well as functions which identify and remove large gaps within the text and special characters.
Additionally, PyTesseract is not perfect and can misidentify certain characters, often mistaking a W for two V's (VV). As mistakes such as these are accumulated, they are added towards a list of common mistakes that Cornucopia checks for prior to sending the data back to the user. Some receipts also abbreviate product and company names, which are corrected through a similar process.
Custom (accuracy) Testing Framework
The consistency and performance of the above systems were thanks to the extensive testing that I conducted during the development of this project. Cornucopia was developed using test-driven development. To test the accuracy and performance of reading and filtering text, I created a custom unit testing framework on top of Python's unittest. The framework tests the text by comparing what is read and filtered with what the tester provides in a .txt document. The tester provides an accuracy score, and if the score calculated by the framework is lower than the provided score, the test fails. Accuracy is determined by looking at the differences in frequency of the characters that appear in the document and sentence structure, as well as individual words within the strings. Finally, in order to easily see where the descrepencies originate from, the framework generates a seperate .txt files with the descrepencies highlighted.
Missing characters are highlighted using []. For example, if the program receives "nucopia is amazing" instead of "cornucopia is amazing", the output file will display "[c][o][r]nucopia is amazing"
Misidentified characters are highlighed using {}. For example, if an extra character was in a line, it would be flagged as unnessessary like "cornucopia is amazing{!}". If a characteris misidentified, the correct character would be displayed as well "cor{n(m)}ucopia is amazing"
Recipe Finding
Recipes are stored in the backend as a graph, which each node in the graph being an ingredient, and clusters of interwoven nodes representing a dish. In order to find recipes that use items from the user's pantry, a DFS is conducted on the graph, where nodes are only traversed if they are within the users pantry. This DFS identifies recipes that can be made, which are stored and compared, based on how many pantry items they use that are near expiry. This is accomplished by adding recipes to a priority queue, and after the search is done the head node is returned. Overall, this process takes O(nlogn), where n is the size of the user's pantry.
Recall Identification
Recalls are found by calling the API's of government institutions. This happens on the server daily, however the user can request an immediate recall check if they so please. If a recall is found, Cornucopia searches its database to see if any users have that item, and if they do, notifies them that their pantry contains recalled items.
Backend + Frontend
Since this is my first Full Stack project, this has been an experience in learning the technologies. Due to this, there is not that much problem-solving as with the other sections.
The database was created using Django Models, however some MySQL was also written. The frontend was created using the React Framework.